Athina AI Research Agent
AI Agent that reads and summarizes research papers
Table of Contents

Original Paper: https://cdn.openai.com/llm-critics-help-catch-llm-bugs-paper.pdf
By: OpenAI
Abstract:
Reinforcement learning from human feedback (RLHF) is fundamentally limited by the capacity of humans to correctly evaluate model output. To improve human evaluation ability and overcome that limitation this work trains “critic” models that help humans to more accurately evaluate model-written code. These critics are themselves LLMs trained with RLHF to write natural language feedback highlighting problems in code from real-world assistant tasks. On code containing naturally occurring LLM errors model-written critiques are preferred over human critiques in 63% of cases, and human evaluation finds that models catch more bugs than human contractors paid for code review. We further confirm that our fine-tuned LLM critics can successfully identify hundreds of errors in ChatGPT training data rated as “flawless”, even though the majority of those tasks are non-code tasks and thus out-of-distribution for the critic model. Critics can have limitations of their own, including hallucinated bugs that could mislead humans into making mistakes they might have otherwise avoided, but human-machine teams of critics and contractors catch similar numbers of bugs to LLM critics while hallucinating less than LLMs alone.
Summary
Blog Post: Improving AI Reliability with Critic Models for Better Code Evaluation
In the swiftly changing world of artificial intelligence (AI), guaranteeing the reliability of AI-generated outputs is increasingly crucial. This is particularly true for AI models that generate or evaluate code, which can occasionally contain subtle bugs or errors not immediately noticeable. These errors are risky in enterprise environments where accuracy is essential. Introducing critic models, which assess and critique model outputs, offers a promising solution to enhance AI reliability, especially in code evaluation.
Understanding Critic Models
Critic models, such as CriticGPT, are a new development designed to improve the evaluation of AI-generated outputs, including code. Unlike traditional methods that rely on human feedback, critic models use a sophisticated training process to identify errors that humans might miss. However, they also face challenges, such as mistakenly identifying errors that don’t exist.

How Critic Models Are Trained and Evaluated
The training and evaluation of critic models involve several key steps and criteria:
- Comprehensiveness: They must cover all significant issues in the code.
- Critique-Bug Inclusion (CBI): They should pinpoint specific, known bugs.
- Minimizing false positives: Avoiding the identification of non-existent issues.
- Helpfulness and style: The critiques should be constructive and clear.
These models are assessed through blind tests and compared using Elo scores, offering a detailed analysis of their performance.
Training Process
Training critic models involves generating critiques for code, which are then rated by human evaluators. These ratings help train a reward model that further refines the critic models' accuracy.
Breakthrough Results with Critic Models
Critic models have shown promising results. For instance, CriticGPT has surpassed human evaluators in identifying bugs, indicating a significant advancement in AI-assisted code evaluation. Combining these models with human evaluators leads to even better performance. Additionally, techniques like Force Sampling Beam Search have improved the balance between detecting real and imagined issues, enhancing evaluation reliability.
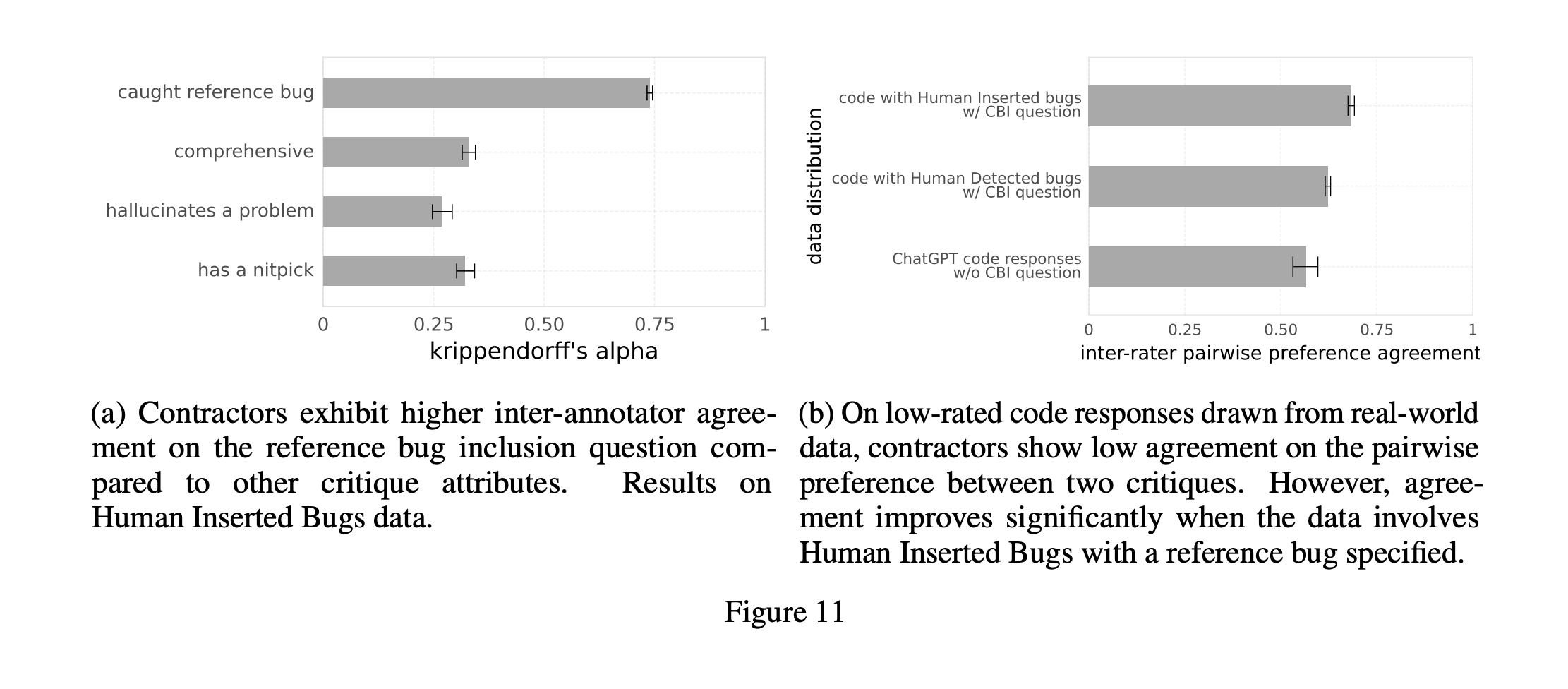
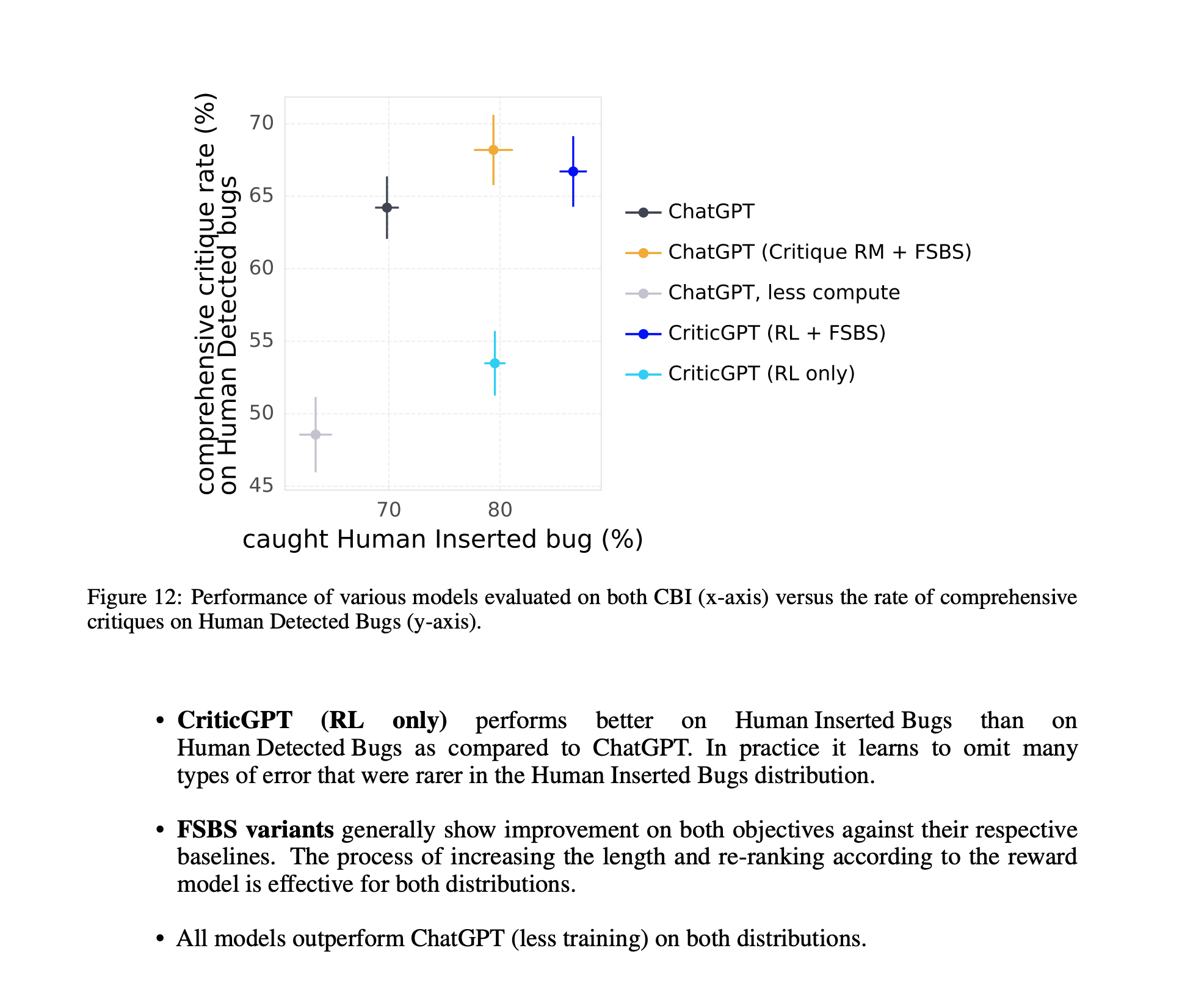
Expanding the Use of Critic Models
The application of critic models in code evaluation is just the beginning. These models are part of broader research into making AI more self-corrective and reliable across various coding tasks. Understanding their role helps us see their potential to revolutionize the field.
Future Directions and Challenges
Critic models are paving the way for AI that is not only more reliable but also capable of self-assessment. However, challenges such as potential biases and distinguishing between different types of errors need to be addressed.
Conclusion
Critic models offer a significant improvement in ensuring the reliability of AI-generated code. By critiquing and evaluating code more accurately, they enhance human evaluators' ability to spot and fix errors. As we refine these models, we edge closer to AI systems that are not just effective but also inherently safe. For AI engineers in enterprise settings, this represents an exciting opportunity to lead in the application of critic models, contributing to the development of AI that is both powerful and dependable. This journey marks a step towards a future where AI and humans collaborate more seamlessly, unlocking new possibilities.
Written by


