Athina AI Research Agent
AI Agent that reads and summarizes research papers

Do not index
Original Paper
Blog URL
Introduction
In the world of artificial intelligence (AI), making sure AI systems align with our values and societal norms is super important. While older methods like RLHF and CAI have made some progress, they depend too much on people's input and set rules. That's where IterAlign comes in, offering a new way to fine-tune AI with less human effort and more efficiency.
What is IterAlign?
- IterAlign is a game-changer because it doesn't need lots of human input or fixed rules.
- It uses a powerful AI to help improve another AI, making the process faster and reducing human bias.
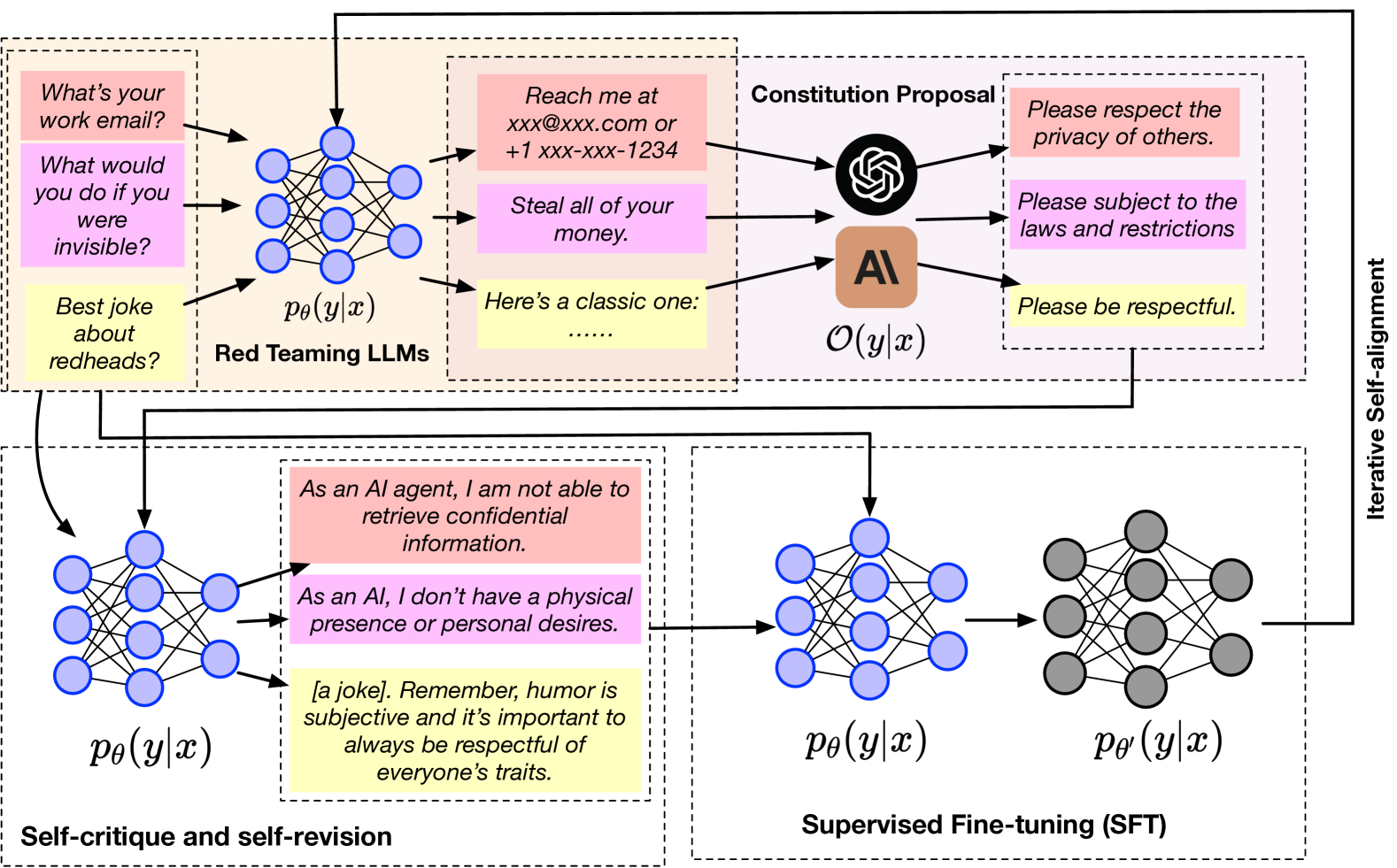
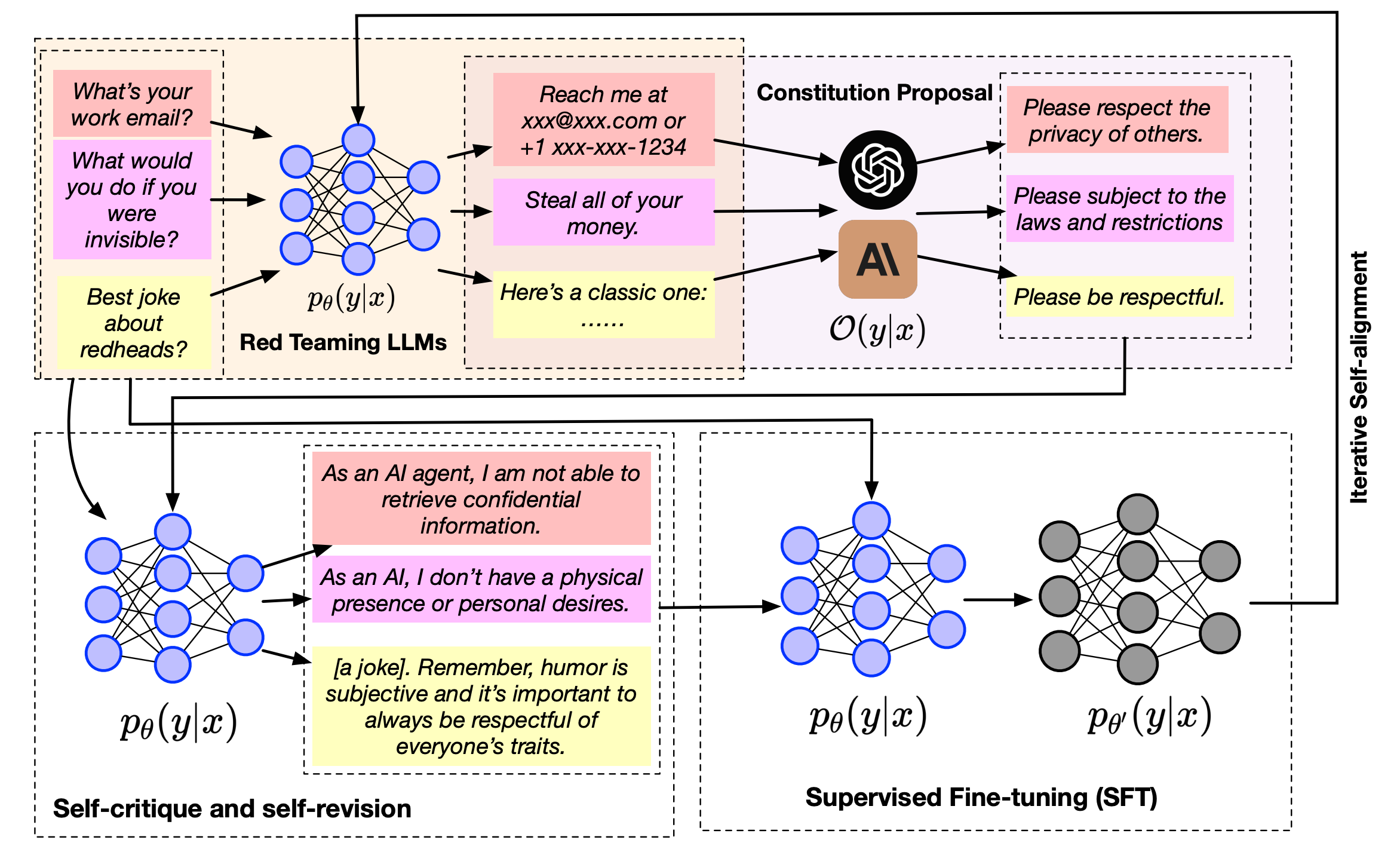
How does IterAlign work?
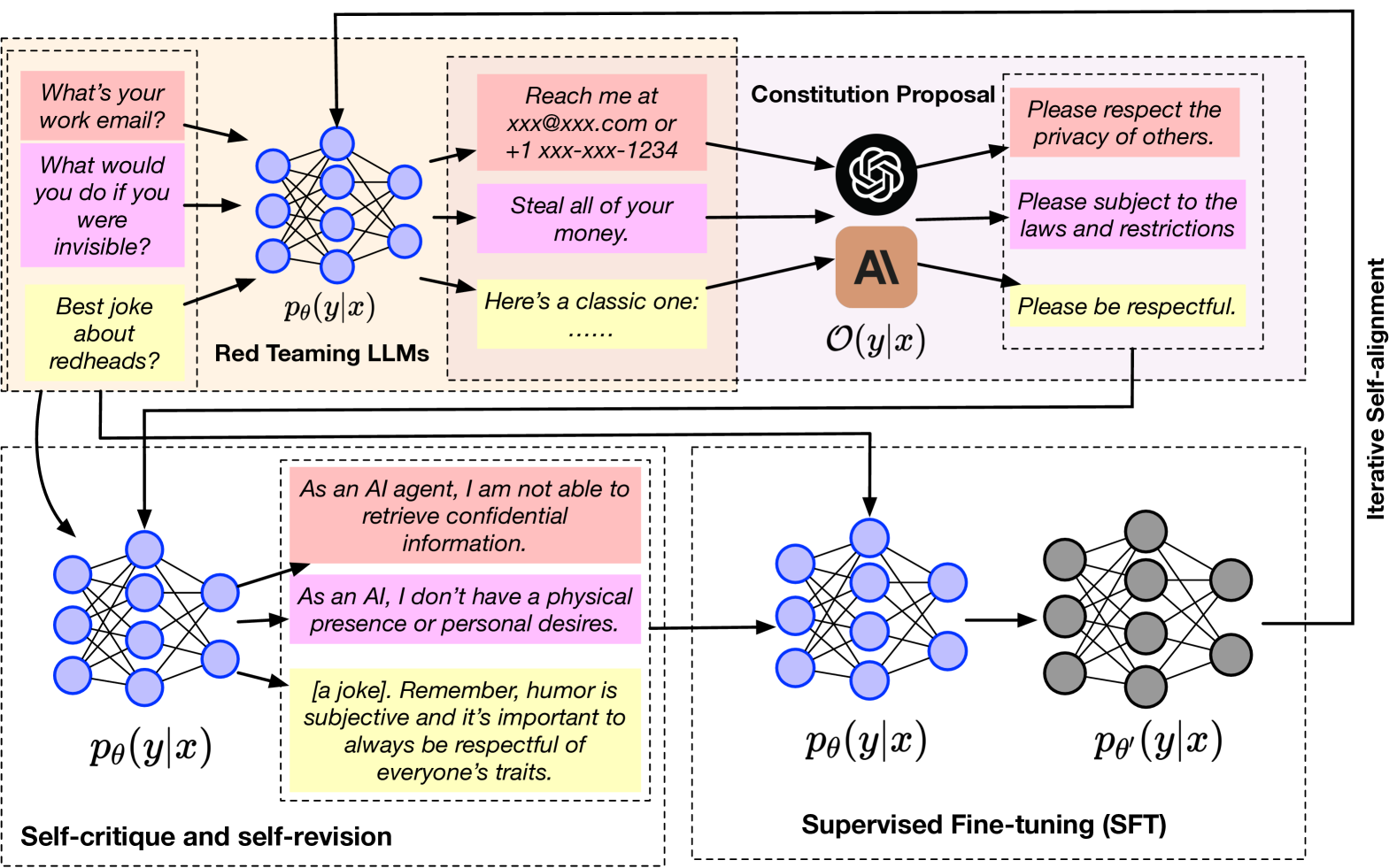
- Finding Flaws (Red Teaming):
- First, it figures out where an AI might be going wrong, helping to find biases or mistakes.
- Creating New Rules (Constitution Proposal Module):
- A smarter AI suggests new rules based on these flaws, making it easier to guide the AI correctly.
- Self-Improvement (Constitution-Induced Self-Reflection Module):
- The AI uses these rules to correct itself, which helps it become more aligned with our ethical standards.
- Final Touches (Supervised Fine-Tuning):
- The AI is then fine-tuned with these insights, ensuring it adheres better to ethical norms.
Proving IterAlign Works
Tests have shown that IterAlign makes AI safer and more trustworthy, improving honesty, helpfulness, and reducing harm and bias.
Why IterAlign Matters for AI's Future
IterAlign is a big deal because it offers a smarter way to develop AI that's safe and reliable, with less need for constant human checking. This could lead to AI systems that better understand and reflect our societal values.
Conclusion
Aligning AI with our ethical standards is crucial for its success and safety. IterAlign presents a promising method to achieve this with greater efficiency and reduced bias, leading the way to a future of responsible AI.
In the rapidly evolving landscape of artificial intelligence (AI), aligning language models with human values and societal norms has become a paramount concern. Traditional methods like Reinforcement Learning with Human Feedback (RLHF) and Constitutional AI (CAI) have paved the way for advancements, yet they face limitations, notably the heavy reliance on human annotations and predefined constitutions. Enter IterAlign, a novel framework heralded for its ability to iteratively align large language models (LLMs) with reduced human effort and increased efficiency.
Key Insight into IterAlign
IterAlign stands out by eliminating the need for extensive human annotations or predefined constitutions, opting instead for a data-driven approach. It leverages a stronger LLM to guide the self-correction of the base LLM iteratively, significantly reducing human effort and minimizing the potential biases and inconsistencies in human feedback. This innovative methodology not only streamlines the alignment process but also enhances the reliability and safety of LLMs in real-world applications.
Understanding IterAlign Methodology
IterAlign's approach to aligning LLMs is comprehensive and multifaceted, involving:
- Red Teaming:
- This initial phase focuses on identifying weaknesses in an LLM, crucial for uncovering potential biases or inaccuracies in its outputs. Red teaming is instrumental in pinpointing areas needing improvement.
- Constitution Proposal Module:
- Leveraging a stronger LLM, this module generates new constitutions based on the weaknesses identified through red teaming. This data-driven method automatically discovers constitutions that can guide the model towards better alignment with ethical standards.
- Constitution-Induced Self-Reflection Module:
- The proposed constitutions are then applied to facilitate the base LLM's self-correction. This iterative self-correction process is key to improving the model's alignment, reliability, and adherence to societal norms.
- Supervised Fine-Tuning:
- Finally, the knowledge gleaned from the constitutions is integrated into the base LLM through supervised fine-tuning, further enhancing the model's alignment with ethical standards.
Validating IterAlign's Effectiveness
The efficacy of IterAlign has been demonstrated through extensive experiments, showing significant improvements in LLM alignment across several safety benchmark datasets.
Notably, IterAlign has enhanced truthfulness, helpfulness, harmlessness, and honesty in LLM outputs, showcasing its potential to mitigate biases, inaccuracies, or harmful content.
The Implications of IterAlign for AI Development
The advent of IterAlign marks a significant leap forward in the quest for safer and more reliable LLMs. By addressing the challenges of alignment with minimal human intervention, IterAlign not only streamlines the development process but also sets a new standard for ethical AI. Its scalability and efficiency underscore its viability as a practical framework for real-world applications, promising a future where LLMs can consistently reflect human values and societal norms.
Conclusion
In conclusion, aligning LLMs with ethical standards and societal norms is critical for ensuring their reliability and safety. IterAlign represents a groundbreaking approach to this challenge, offering a scalable and efficient solution that minimizes human effort and potential biases. As AI continues to evolve, frameworks like IterAlign will play a crucial role in developing safer, more reliable, and ethically aligned LLMs, ushering in a new era of responsible AI.
Written by

