
Do not index
Original Paper
Blog URL
Using advanced prompting techniques can significantly enhance the quality and accuracy of responses generated by your LLM-based applications.
Here are five advanced prompting techniques that can help you and your team improve your LLM app’s performance: Chain-of-Thought, Tree-of-Thoughts, Reflexion, ReAct, and Self-Consistency.
1. Chain-of-Thought
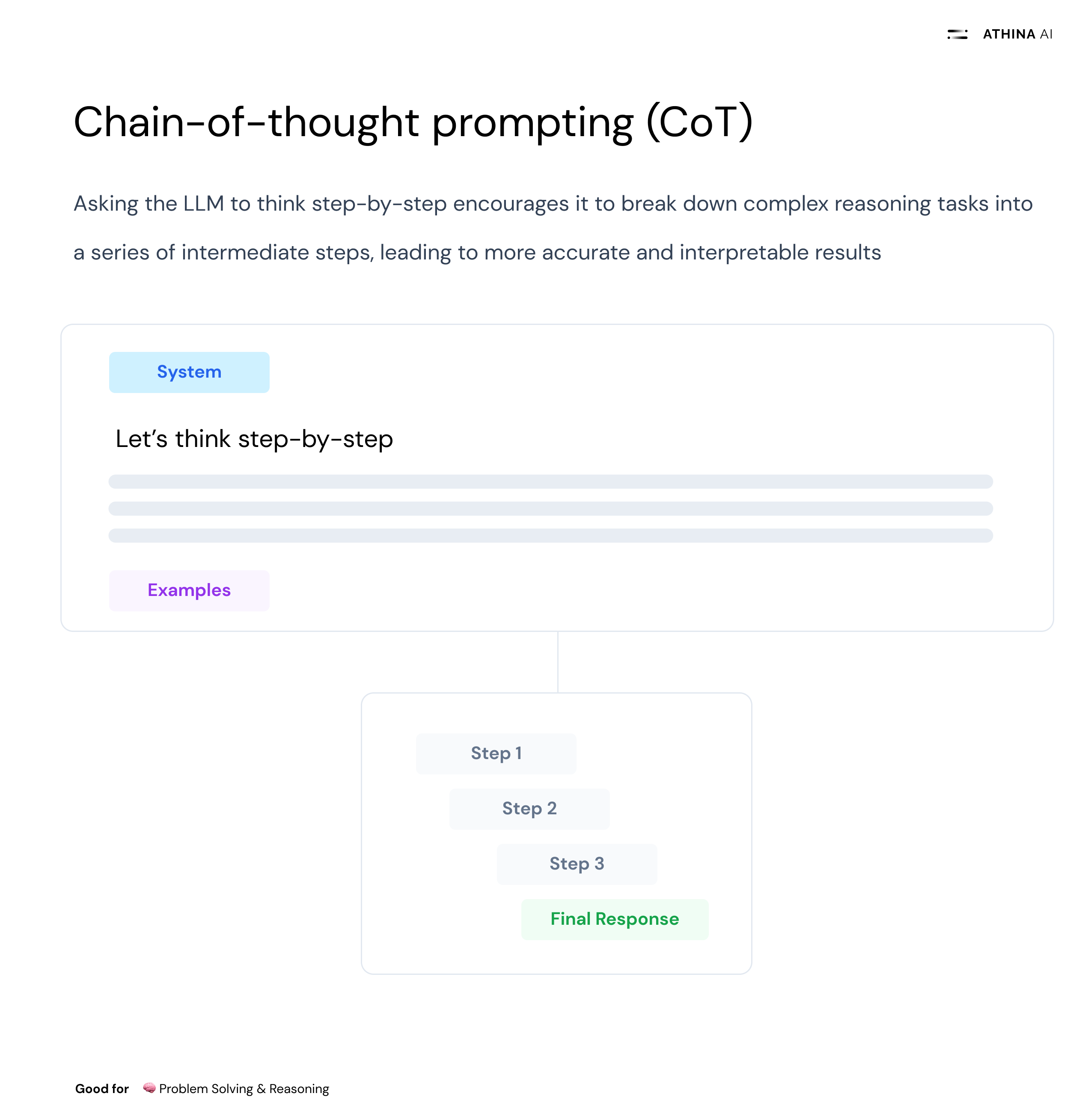
What is it?
Chain-of-Thought (CoT) prompting breaks down the reasoning process into intermediate steps, mimicking human logical progression. This helps the model solve complex problems step-by-step.
How to Implement
Structure your prompts to encourage the model to explain its reasoning as it arrives at an answer. For example, instead of asking, "What is the sum of 135 and 246?" prompt with, "First, add the hundreds place, then the tens place, and finally the ones place to find the sum of 135 and 246."
Benefits
- Improved Accuracy: Handles complex questions more effectively.
- Transparency: Easier to debug and refine model reasoning.
2. Tree-of-Thoughts
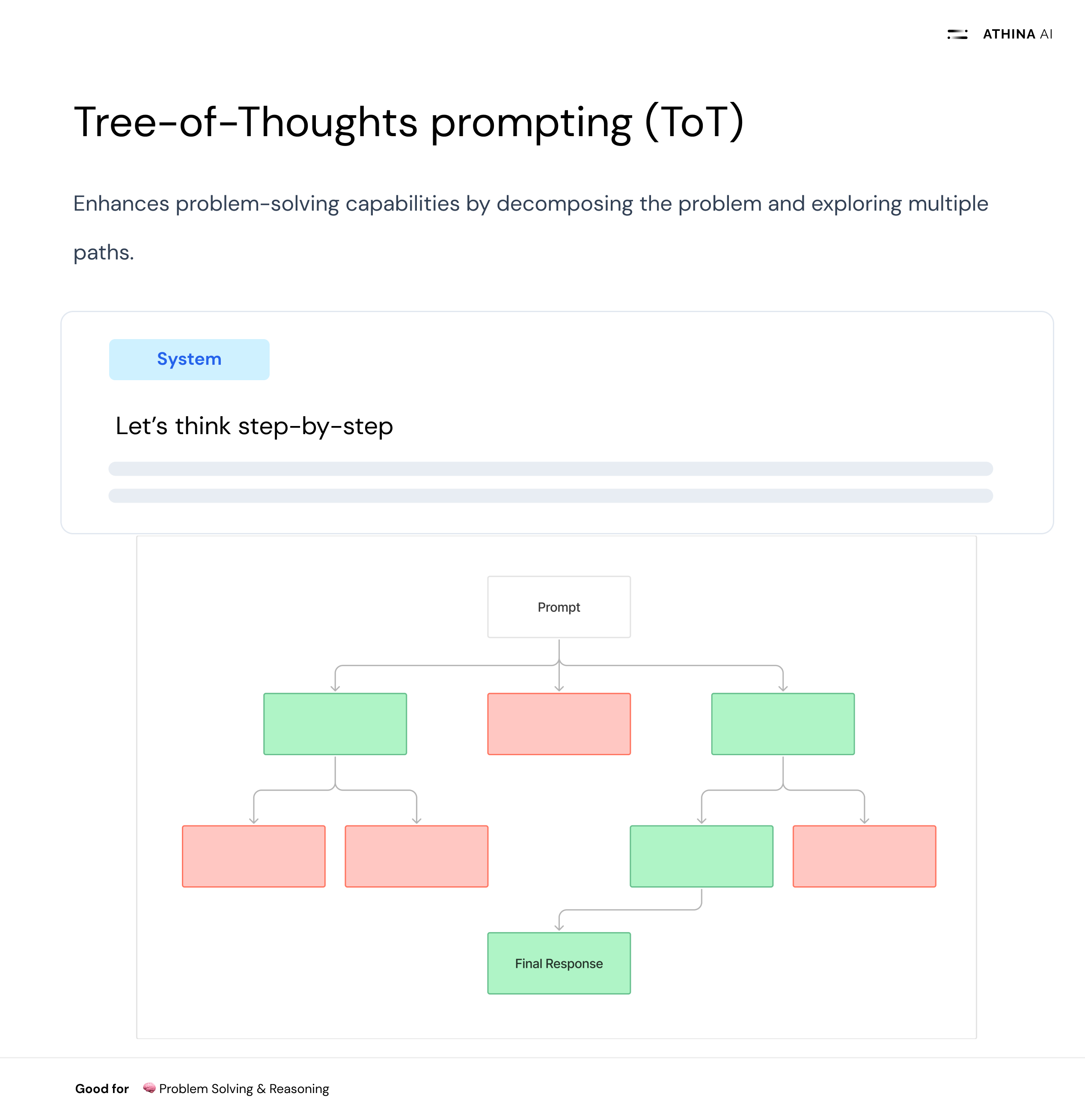
What is it?
Tree-of-Thoughts (ToT) prompting extends CoT by considering multiple potential reasoning paths simultaneously. This helps the model explore different solutions and choose the best one.
How to Implement
Guide the model to generate various possible steps and then evaluate these paths. For example, "Consider different ways to approach solving this math problem: using algebra, graphical methods, or numerical estimation. Then, choose the best method."
Benefits
- Enhanced Problem Solving: Encourages diverse thinking paths.
- Flexibility: Adapts well to problems with multiple solutions.
3. Reflexion
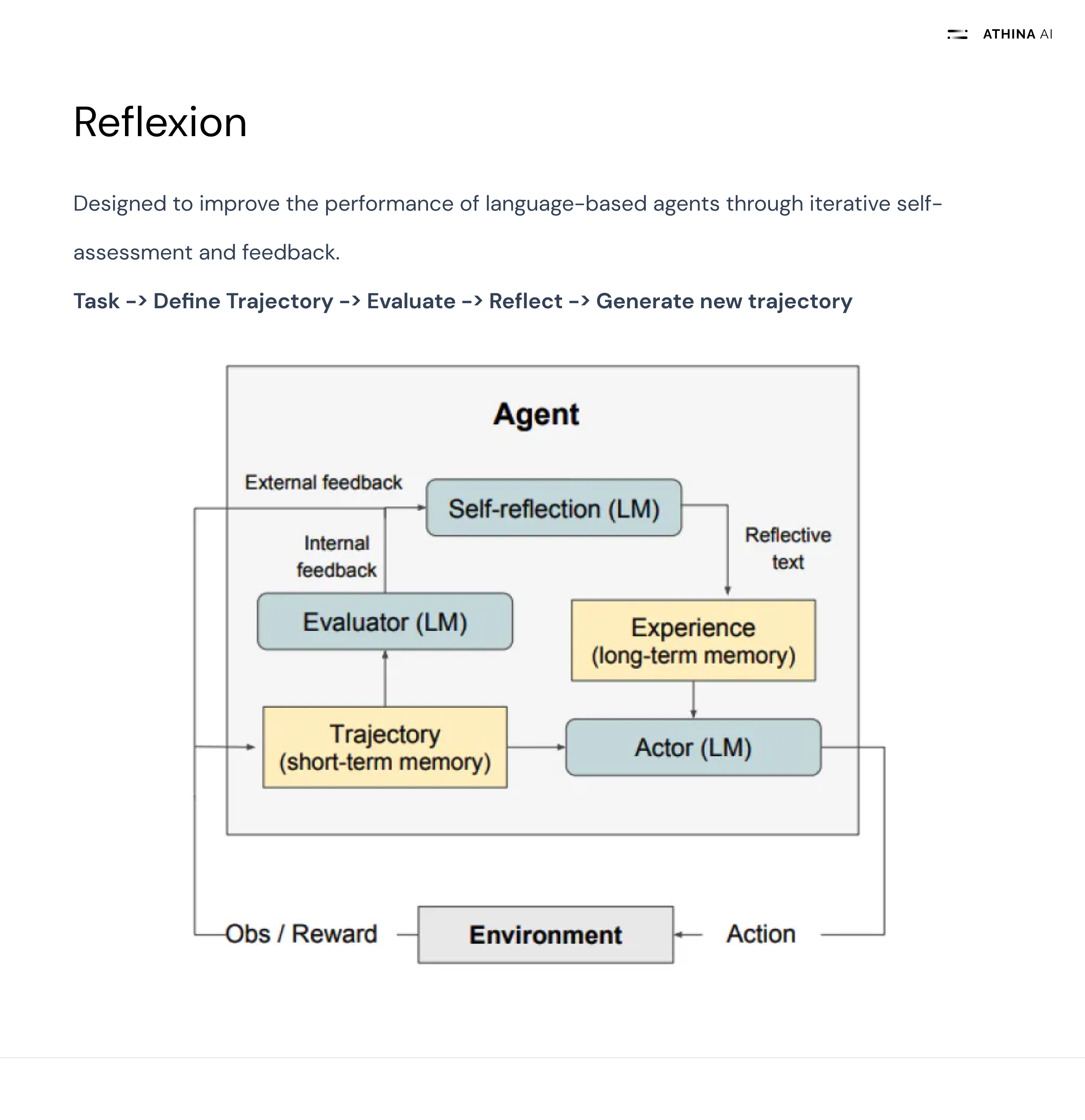
Reflexion is an advanced prompting technique that enhances the performance of language-based AI agents through iterative self-improvement and linguistic feedback.
Reflexion consists of three key components:
- An Actor: This is the main language model that generates responses and actions based on the given input or task. It utilizes techniques like Chain-of-Thought (CoT) and ReAct to produce its outputs.
- An Evaluator: This component assesses the quality of the Actor's output, typically by assigning a reward score. The evaluation criteria depend on the specific task at hand.
- Self-Reflection: This is a crucial element where another language model generates verbal reinforcement cues to help the Actor improve. It analyzes the current trajectory, reward signal, and persistent memory to provide specific and relevant feedback.
The Reflexion process follows these steps:
- Define a task
- Generate a trajectory (Actor's response)
- Evaluate the response
- Perform reflection
- Generate the next trajectory
Reflexion is particularly effective in scenarios where:
- An agent needs to learn through trial and error
- Traditional reinforcement learning methods are impractical
- Nuanced feedback is required
- Interpretability and explicit memory are important
The technique has shown impressive results in various domains:
- Sequential decision-making tasks (e.g., AlfWorld)
- Reasoning tasks (e.g., HotPotQA)
- Programming tasks (e.g., HumanEval and MBPP)
Reflexion outperforms baseline approaches in these areas, demonstrating its effectiveness in enhancing AI performance across diverse problem-solving scenarios.
Reflexion does have some limitations, such as its reliance on the agent's self-evaluation capabilities. Additionally, the technique requires multiple iterations, which may increase computation time and resources compared to single-pass approaches.
Benefits
- Continuous Improvement: Models iteratively learn and enhance their performance.
- Error Correction: Helps in identifying and fixing inaccuracies in responses.
4. ReAct

ReAct Prompting is an advanced technique for interacting with large language models (LLMs) that combines reasoning and action planning to improve the quality and accuracy of results.
This approach aims to replicate human-like cognitive processes by instructing LLMs to generate both reasoning traces and task-specific actions in an interleaved manner
ReAct enables models to adapt their plans based on evolving context during the reasoning process, resulting in more context-aware and responsive behavior.
Benefits
- Reduced Hallucinations: By interleaving reasoning and acting, ReAct aims to reduce fact hallucination and error propagation, leading to more reliable outcomes.
- Improved interpretability: The combination of reasoning and action steps makes the model's responses more comprehensible and trustworthy for human users
- Integration of external knowledge: The technique facilitates interaction with external tools and knowledge bases, allowing the model to incorporate real-time information into its responses.
5. Self-Consistency
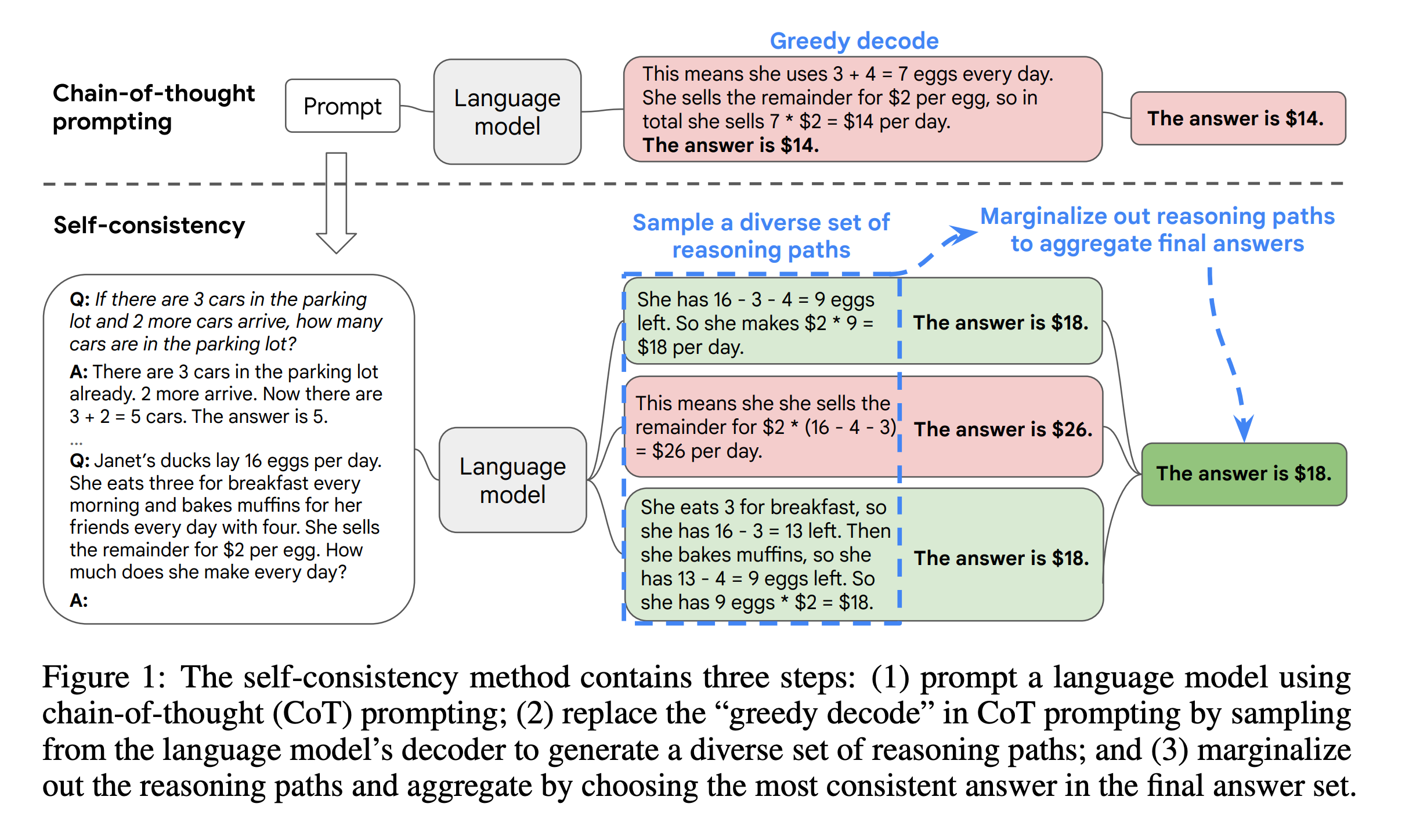
Self-consistency is an advanced prompt engineering technique designed to improve the accuracy of language models, particularly for tasks involving arithmetic and commonsense reasoning. Here's how it works:
- Multiple reasoning paths: Instead of relying on a single chain-of-thought (CoT) response, self-consistency generates multiple diverse reasoning paths for the same problem.
- Few-shot CoT prompting: The technique uses few-shot examples to guide the model in generating these multiple reasoning paths.
- Sampling: The model samples several different solutions to the problem, each potentially taking a different approach or line of reasoning.
- Consistency analysis: The generated solutions are then analyzed for consistency. The most consistent or frequently occurring answer is selected as the final output.
- Performance boost: This approach helps to improve the model's performance by considering multiple perspectives and reducing the impact of individual errors or biases.
The big advantage of self-consistency is that it doesn't rely solely on a single chain of thought, which may be flawed.
Instead, it leverages the power of multiple reasoning attempts to arrive at a more reliable answer. This technique has shown particular effectiveness in tasks involving arithmetic and commonsense reasoning, where a single approach might lead to errors.
In practice, implementing self-consistency involves crafting a prompt with few-shot examples that demonstrate the desired reasoning process, then using this prompt multiple times to generate diverse solutions.
The final step involves analyzing these solutions to determine the most consistent or frequently occurring answer.
Try Athina IDE →
How can you determine which prompting technique will work best for you?
Run experiments using Athina IDE to figure out which is truly best. (Demo Video).
Conclusion
By implementing these advanced prompting techniques—Chain-of-Thought, Tree-of-Thoughts, Reflexion, ReAct, and Self-Consistency—you can significantly boost the performance of your LLM-based applications.
Guide your model’s reasoning, encourage diverse thinking paths, foster self-improvement, enable dynamic interactions, and ensure consistency to create more accurate, reliable, and engaging LLM responses.
Experiment with these methods using Athina IDE to find the best fit for your application and watch your LLM's capabilities soar.
Written by
